A nano-GPT implementation with Pytorch Lightning. The goal is to have a clean building block for other research projects by containing just enough manual implementation do be easily modifiable, but also by using common tools to have a painless optimized training and nice monitoring. Its contains the code to train the model, prepare the dataset and run evals. This page also details results I got training on HF’s FineWeb-Edu.
Model Architecture
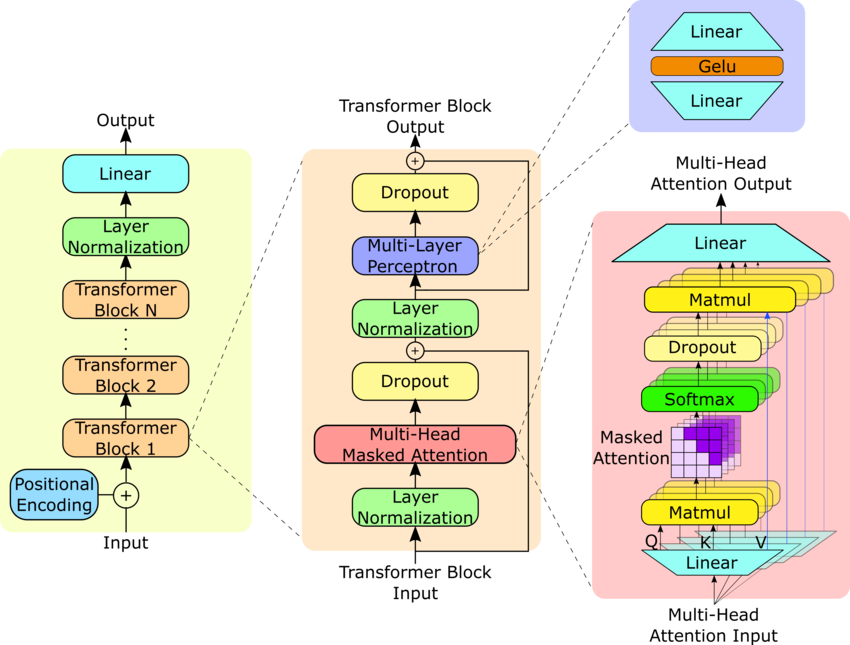
GPT-2 is an autoregressive transformer model using stacked decoder blocks with multi-head self-attention and feed-forward layers. It employs causal masking in attention to maintain the autoregressive property. The model uses learned positional embeddings and weight tying between input and output embeddings.
My implementation is identical to the small GPT2 model but without the dropout layers:
- 50304 vocab size
- 768 embedding size
- 12 heads
- 12 transformer block
This gives us a total of 124M params. Its a causal model so next tokens are mask in the self-attention matrix.
Key components
Causal Self-Attention: The heart of the model is the causal self-attention mechanism. Here’s a streamlined implementation where the unidirectionality is handled by PyTorch:
class CausalSelfAttention(nn.Module): def __init__(self, config: GPTConfig): super().__init__() self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd) self.c_proj = nn.Linear(config.n_embd, config.n_embd) self.n_head = config.n_head self.n_embd = config.n_embd def forward(self, x: torch.Tensor) -> torch.Tensor: B, T, C = x.size() qkv = self.c_attn(x) q, k, v = qkv.split(self.n_embd, dim=2) q, k, v = [t.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) for t in (q, k, v)] y = F.scaled_dot_product_attention(q, k, v, is_causal=True) return self.c_proj(y.transpose(1, 2).contiguous().view(B, T, C))Transformer Blocks: Each transformer block combines self-attention with a feed-forward neural network:
class Block(nn.Module): def __init__(self, config: GPTConfig): super().__init__() self.ln_1 = nn.LayerNorm(config.n_embd) self.attn = CausalSelfAttention(config) self.ln_2 = nn.LayerNorm(config.n_embd) self.mlp = MLP(config) def forward(self, x: torch.Tensor) -> torch.Tensor: x = x + self.attn(self.ln_1(x)) x = x + self.mlp(self.ln_2(x)) return xFull Model Architecture: The complete GPT model assembles these components:
class GPT(nn.Module): def __init__(self, config: GPTConfig): super().__init__() self.transformer = nn.ModuleDict(dict( wte=nn.Embedding(config.vocab_size, config.n_embd), wpe=nn.Embedding(config.block_size, config.n_embd), h=nn.ModuleList([Block(config) for _ in range(config.n_layer)]), ln_f=nn.LayerNorm(config.n_embd), )) self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False) self.transformer.wte.weight = self.lm_head.weight # weight tying
Training
Optimization Techniques Used
Because the implementation has been made with Pytorch Lightning we can easily incorporate several optimization techniques:
- Scheduled Learning Rate: Warmup and cosine annealing like in the GPT-3 paper
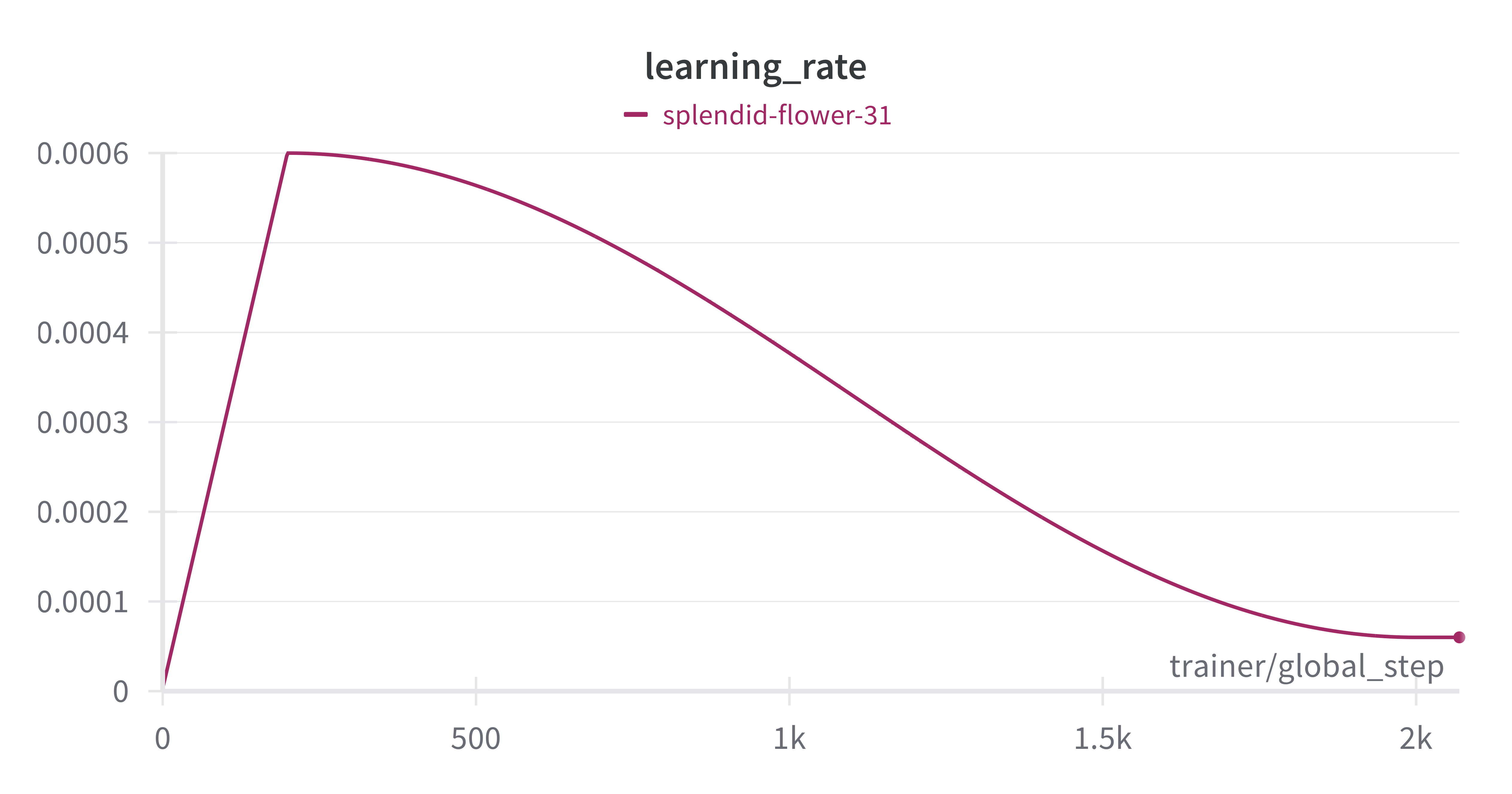
- Mixed Precision: BF16 mixed precision to for computational efficiency and memory usage.
- Gradient Clipping: Set to 1.0 like in the GPT-3 paper.
- Weight Decay: Set to 0.3, I found that a bigger number than in the GPT-3 paper (0.1) work better in my case.
- DDP (Distributed Data Parallel): Facilitates parallel data processing on multiple GPUs, accelerating training times significantly.
Dataset
For this project, I developed a custom HuggingFacePreparedTextDataset class to efficiently process the 10B token subset of HuggingFace’s FineWeb-Edu dataset. Key features include:
- Efficient Storage: Using uint16 for token storage optimizes memory usage.
- Sequence Generation: Each sample is a sequence of tokens, with inputs and targets created by sliding a window:
def __getitem__(self, idx): # ... (document and token retrieval) buf = tokenized_doc[start_idx:end_idx] x = buf[:-1] # inputs y = buf[1:] # targets return torch.from_numpy(x.astype(np.int64)), torch.from_numpy(y.astype(np.int64)) - On-the-fly Processing: Documents are tokenized and sampled on demand, allowing for datasets larger than available storage:
def __getitem__(self, idx): doc_idx = next(i for i, count in enumerate(self.cumulative_samples) if count > idx) - 1 document = self.dataset[doc_idx] tokenized_doc = self.tokenize(document) start_idx = (idx - self.cumulative_samples[doc_idx]) * self.sequence_length end_idx = start_idx + self.sequence_length + 1 buf = tokenized_doc[start_idx:end_idx] - Worker-Aware Iteration: The iter method from the
HuggingFacePreparedTextDatasetclass handle sharding across workers in multi-process data loading:def __iter__(self): worker_info = torch.utils.data.get_worker_info() if worker_info is None: # single-process data loading iter_start, iter_end = 0, len(self.dataset) else: # in a worker process per_worker = int(math.ceil(len(self.dataset) / float(worker_info.num_workers))) worker_id = worker_info.id iter_start = worker_id * per_worker iter_end = min(iter_start + per_worker, len(self.dataset)) [...]
This implementation balances efficiency with flexibility, allowing for processing of large-scale datasets while maintaining compatibility with standard PyTorch training pipelines.
Results
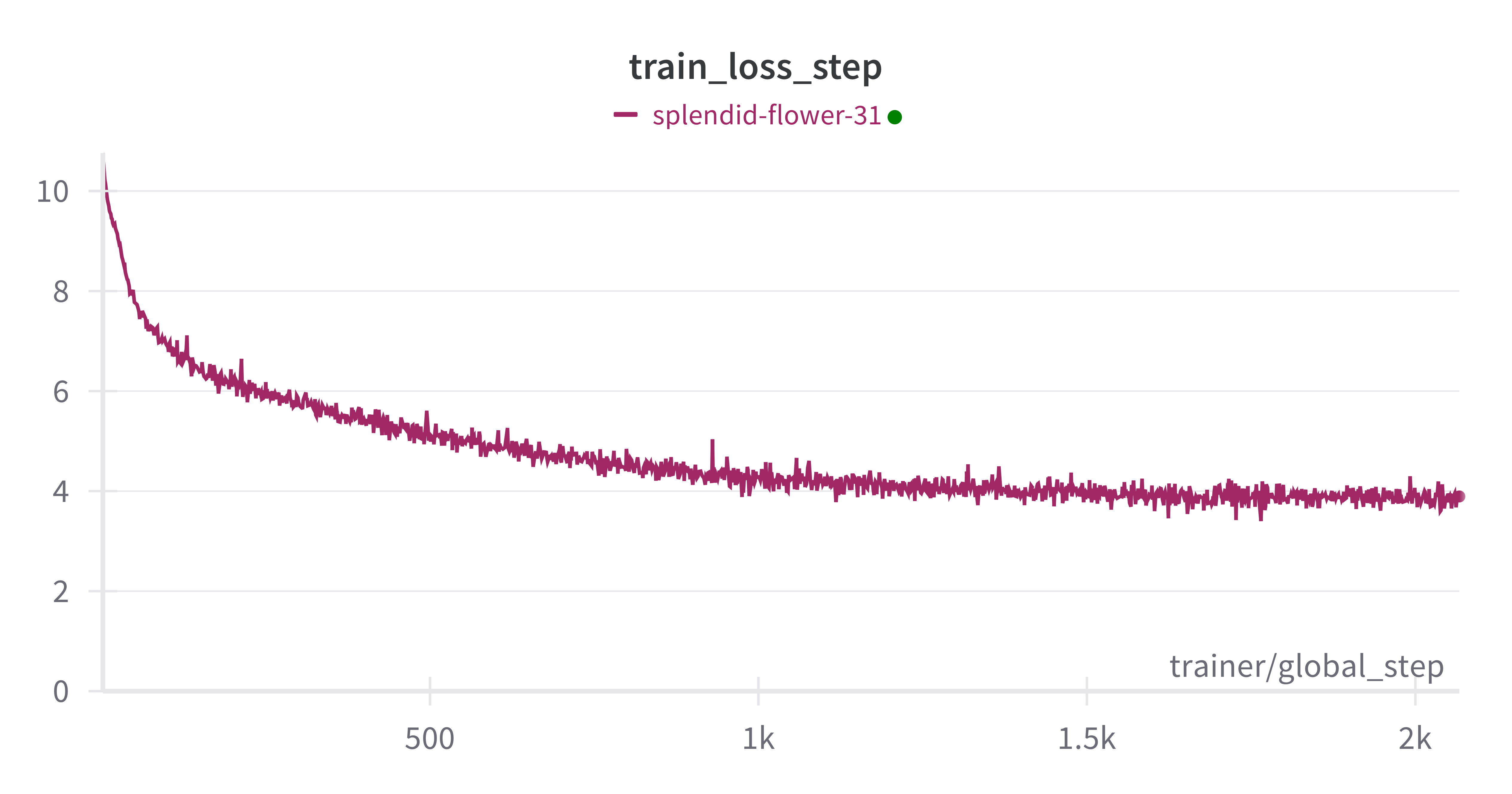
Given that GPUs were rented, the goal was just to verify the pipeline’s functionality. A brief training run of 2,000 steps was conducted on a small subset of data to demonstrate the system’s operability. The resulting loss curve shows a typical decreasing pattern, indicating that the training process is working as expected.
How to Use This Implementation
For detailed instructions on how to use this implementation, refer to the GitHub repository, which includes comprehensive documentation on setup, configuration, and execution.