Quadrupeds robots currently have difficulty overcoming rough terrains, the goal of this project is to improve the agility and robustness of legged locomotion over complex terrain using reinforcement learning. The project consists of implementing the following paper from Nvidia Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning and adapt it to the unitree A1

Problem statement
Traditionnaly locomotion is achieve through Optimization algorithms, especially Model Predictive Control (MPC). MPC is a feedback control algorithm that uses a system model to predict future behavior and optimize control inputs for desired trajectories. For robots, such as in MIT’s Cheetah 3 project (Dynamic Locomotion in the MIT Cheetah 3 Through Convex Model-Predictive Contro) the control task is framed as a convex optimization problem to minimize trajectory errors and control efforts within friction constraints.
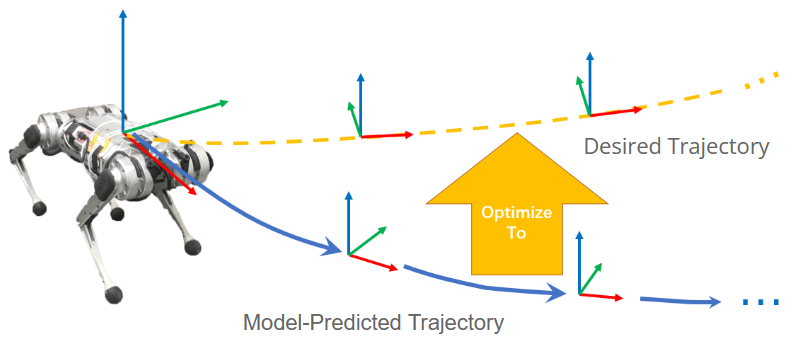
While MPC effectively manages dynamic motions, its dependence on accurate models limits its use on complex terrains without satisfactory interaction models between the ground and robot feet. This is where learning-based methods such as Reinforcement Learning (RL) can come into play
RL Training
Strategy
The general framework of the reinforcement learning algorithm is based on the Markov decision process (MDP). In this process, our robot takes some actions to change the current state, and then gives it some rewards or punishments based on whether the state is good or bad. The goal of the agent is to maximize some notion of cumulative reward over a trajectory. We use the Proximal Policy Optimization (PPO) algorithm restricts the change in the policy to a specified range to prevent excessively large updates. Here is how our problem is set up:
Obersvation Space = {Body linear velocity, Body angular velocity, Projected gravity vector, Commands, Joint position, Joint velocity, Previous action}
Action Space = {Joint Position} (12)
Reward = {Termination, Orientation, Tracking lin velocity, Tracking ang velocity, Feet air time, Tight divergence, Abduct divergence}
Curriculum
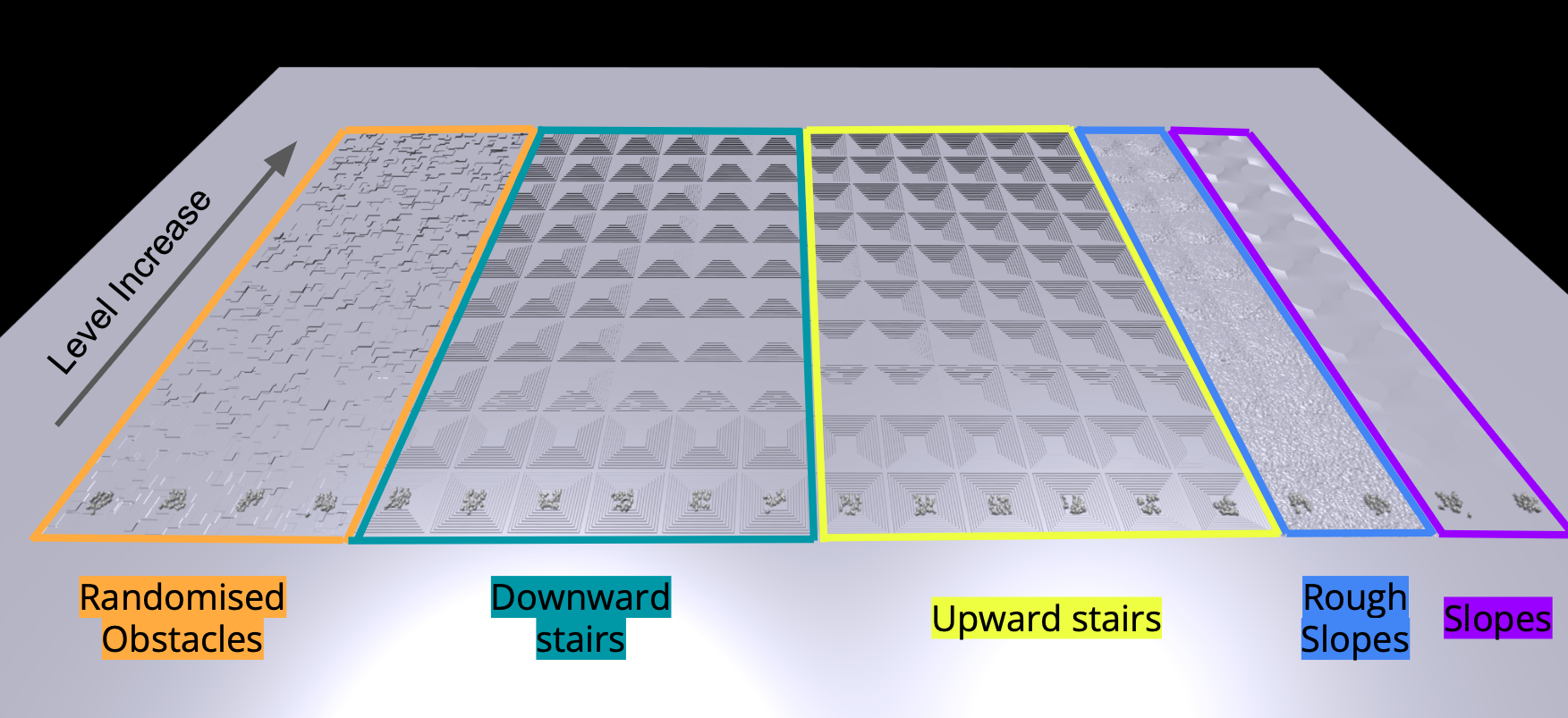
20000 simulated robots are trained in parallel on different terrain in Isaac Gym. The parallelization was achieved by averaging the gradients between the different workers. Every 50 steps (inference), the policy is updated by batch. Terrains increase in difficulty, those with stairs and randomized obstacles have a step height going from 5 cm to 20 cm and those with inclination go from 0 deg to 25 deg.
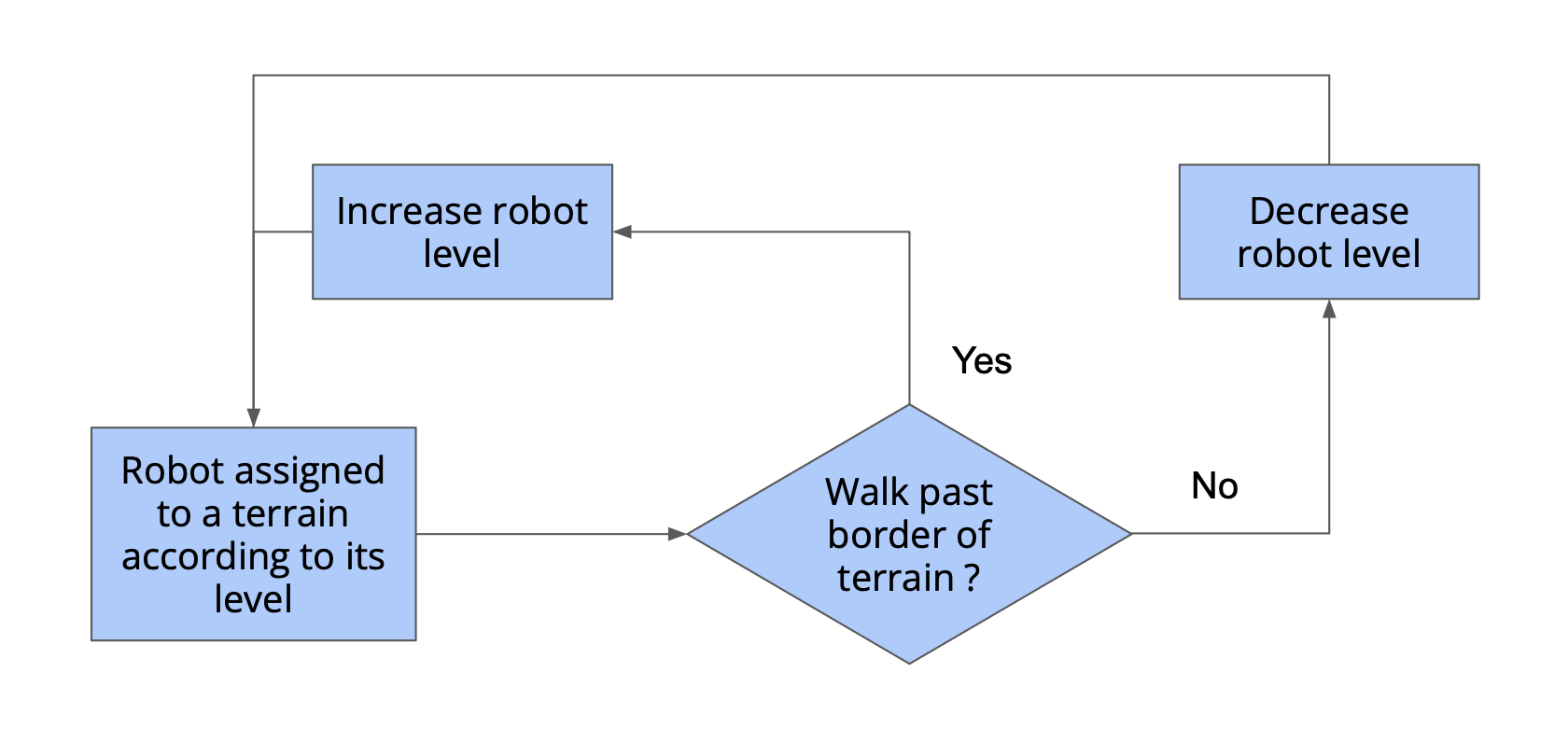
To adapts the task difficulty to the performance of the policy the authors of Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning propose a game inspired curriculum. If a robot successfully walks beyond the boundaries of its designated area, its level increases, and upon the next reset, it will begin on more challenging terrain. Conversely, if at the end of an episode the robot covers less than half the distance dictated by its target velocity, its level decreases. Robots that conquer the highest level are reassigned to a randomly selected level to enhance diversity and prevent catastrophic forgetting.
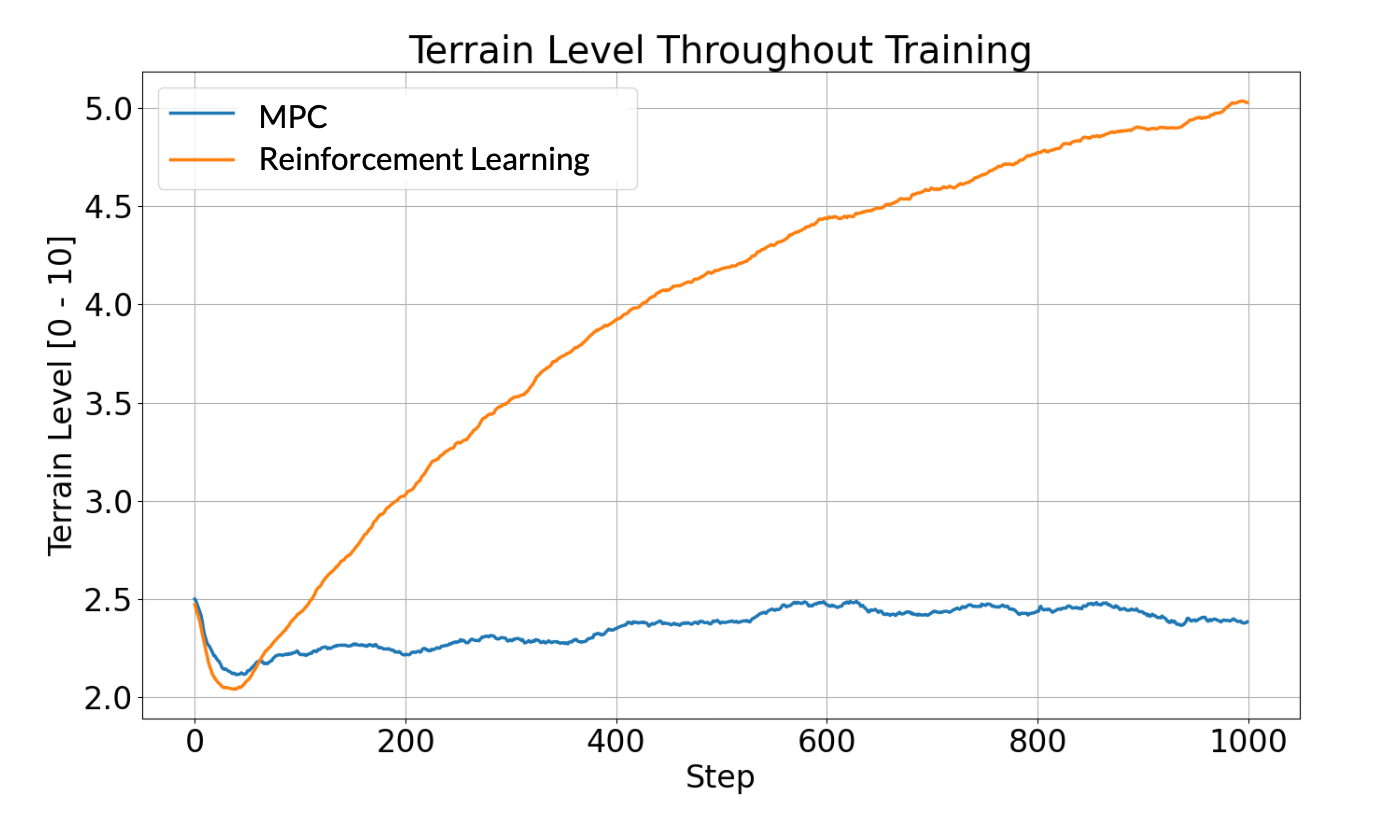
Results
We can clearly see the supperiority of RL for locomotion during training. Control based policy is stuck at lower terrain levels while the learning based policy reach easily the 5th terrain (training stop due to training costs).
After implementation we can also clearly see how the learning based gait looks more natural than the control based.
RL:

MPC:
