A simple Pytroch U-Net implementation. The goal is to have an clean building block that can be used in other bigger projects (e.g. Diffusion). The model is tested with a segmentation task on the MIT scene-parse-150 dataset.
Architecture
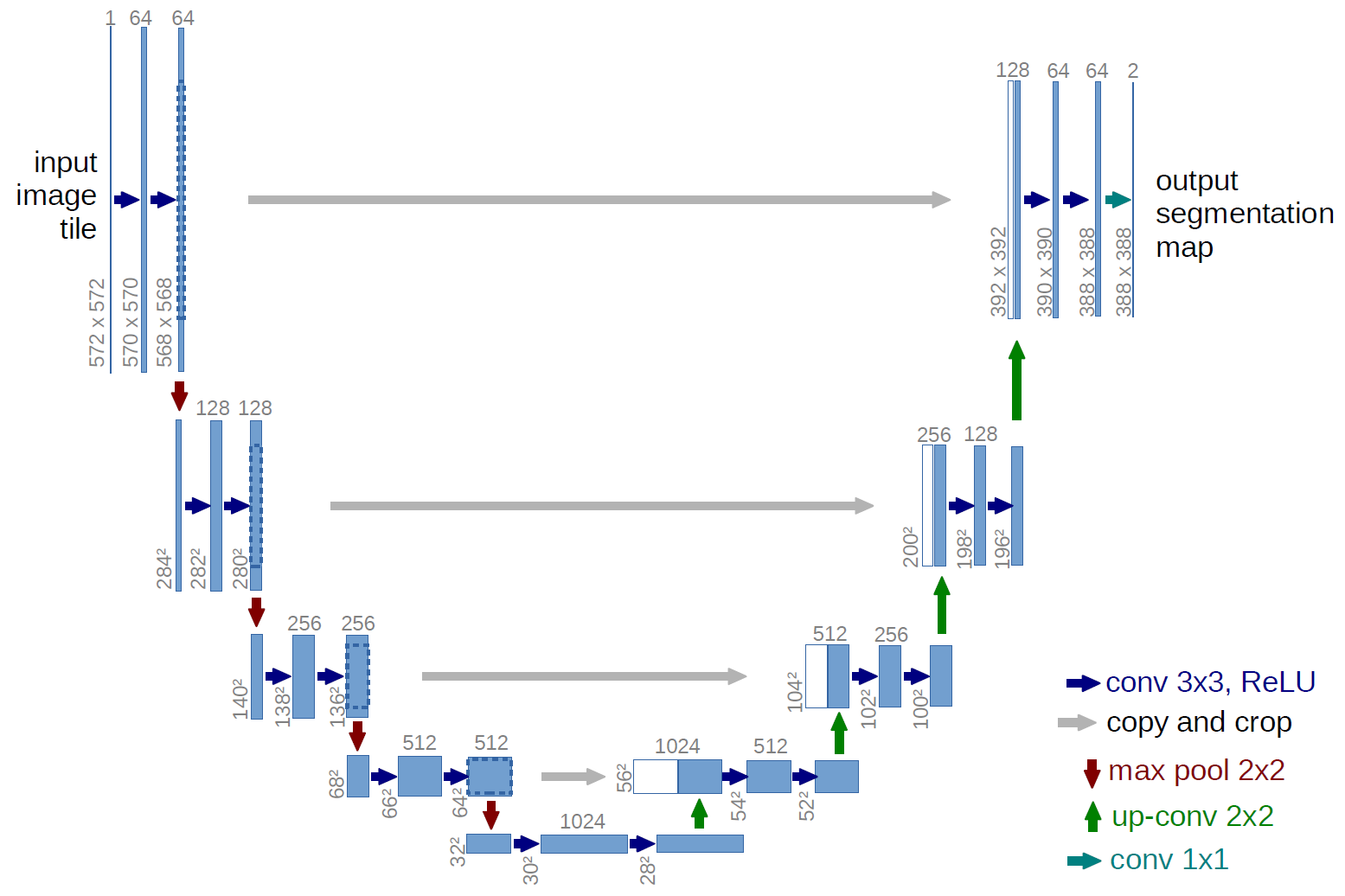
The network is built up as follows:
The network consists of a downsampling path, a bottleneck, and an upsampling path.
In the downsampling path:
- A sequence of DoubleConv modules are applied. Each DoubleConv consists of two convolutional layers, each followed by batch normalization and GELU activation.
- After each DoubleConv, a max pooling operation is applied to reduce the spatial dimensions.
class DoubleConv(nn.Module): def __init__(self, in_channels, out_channedls): super(DoubleConv, self).__init__() self.conv = nn.Sequential( nn.Conv2d(in_channels, out_channels, 3, 1, 1, bias=False), nn.BatchNorm2d(out_channels), nn.GELU(approximate="tanh"), nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False), nn.GELU(approximate="tanh"), ) def forward(self, x): return self.conv(x)
At the bottom of the network, a bottleneck DoubleConv is applied, doubling the number of channels.
In the upsampling path:
- A sequence of transposed convolutions are applied to increase the spatial dimensions.
- The output of each transposed convolution is concatenated with the corresponding skip connection from the downsampling path.
- Another DoubleConv is applied after each concatenation.
Finally, a single convolutional layer is applied to produce the output with the specified number of channels.
Dataset
The scene_parse_150 dataset, part of the MIT Scene Parsing Benchmark (ADE20K), contains over 20,000 images with pixel-wise annotations across 150 semantic categories. This diverse dataset, featuring both indoor and outdoor scenes, provides a challenging testbed for semantic segmentation models like U-Nets.

This dataset is quite heterogenous regarding the image shapes and encoding, some light transformations are thus necessary to be able to train on it
self.image_transform = transforms.Compose(
[
transforms.Lambda(lambda img: img.convert("RGB")),
transforms.Resize(image_size),
transforms.Lambda(lambda img: pil_to_tensor(img)),
transforms.Lambda(lambda t: t.float() / 255.0),
]
)
self.mask_transform = transforms.Compose(
[
transforms.Resize(image_size, interpolation=Image.NEAREST),
transforms.Lambda(lambda img: pil_to_tensor(img)),
]
)
Training
Loss
The dataset contains 150 semantic categories so our model have out_channels = 150. The logits are then shape (N, 150, C, H, W) and our mask shape (N, H, W) containing the indices of the associated classes to the pixels. We then use multi-class cross-entropy for the loss:
image, mask = batch
logits = self(image)
mask = mask.squeeze(1)
loss = torch.nn.functional.cross_entropy(logits, mask)
Run
The goal here is not to actually train the model on the whole dataset but instead to show that the pipeline works. The training is then done on a 1k datapoint subset until the model overfit (200 epochs). It took less than 20min on a single A100 GPU.
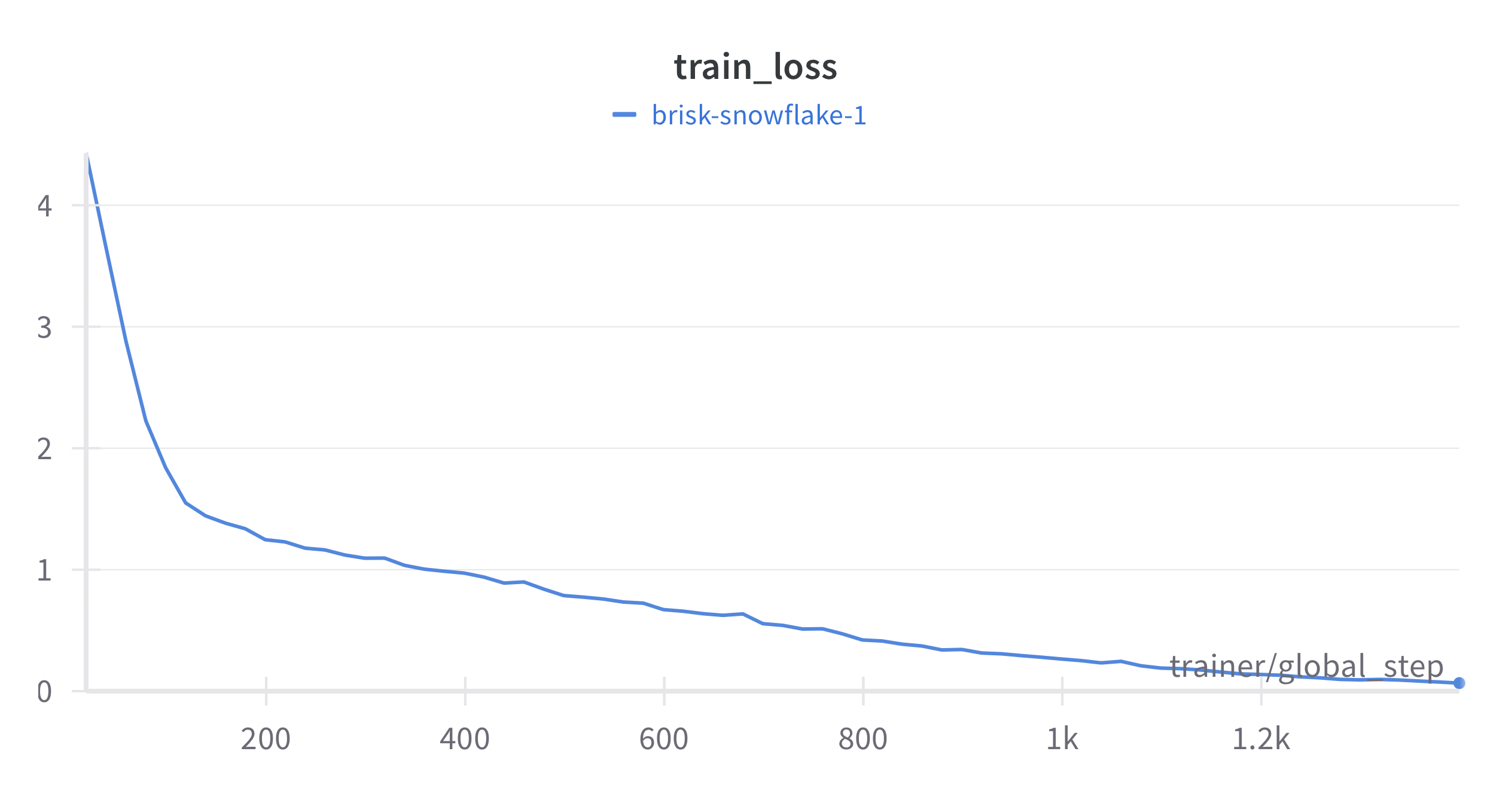
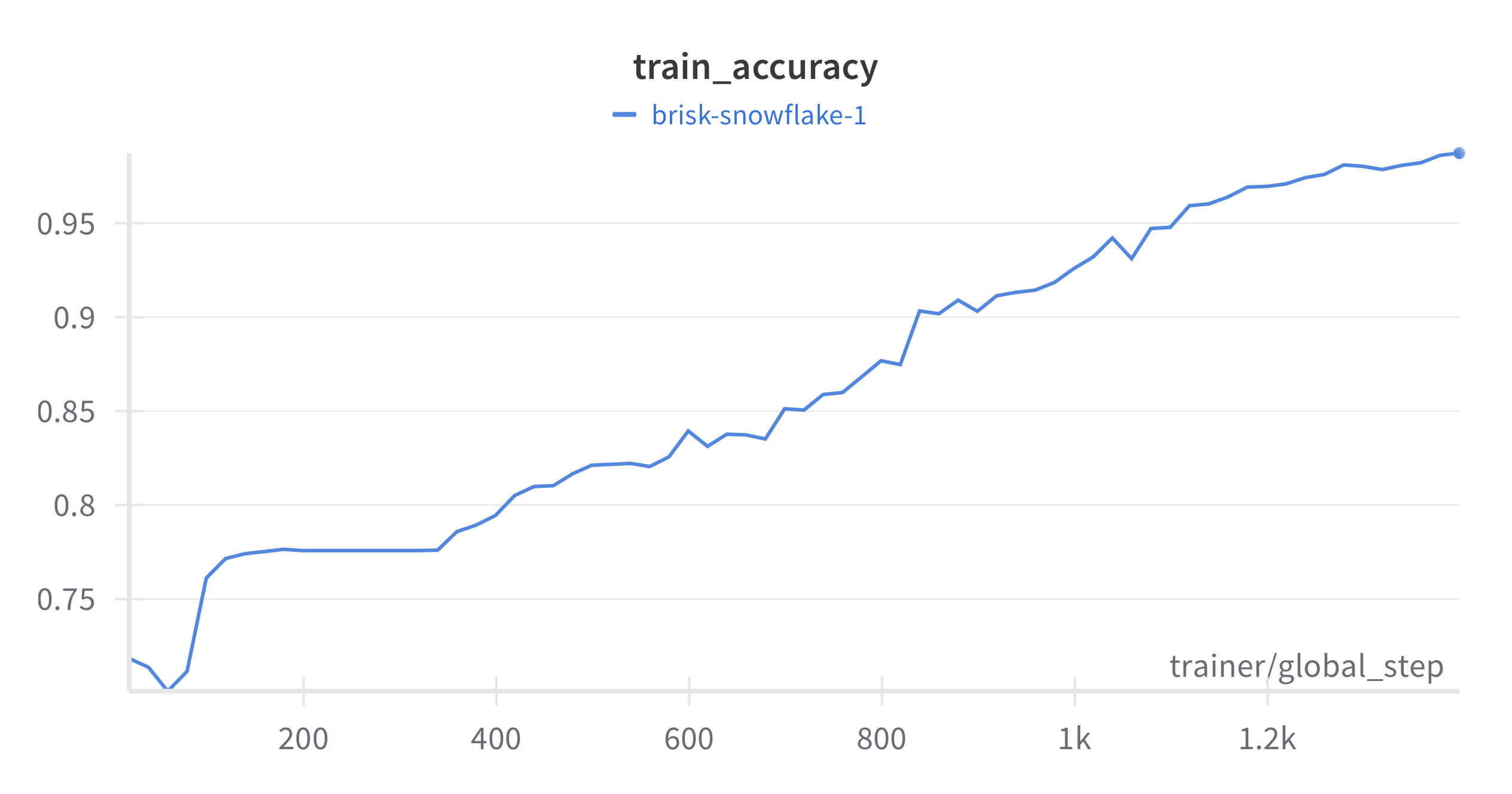
Results
Here are some sample results with the ground truth on the left and the predictions on the right. Given the size of sub-dataset used for training we cannot expect much better
